Bilingual dictionary discovery
This page describes a way of discovering new bilingual, or multilingual dictionaries.
We already have apertium-dixtools for crossing dictionaries, but what happens if you want to make a pair where there are no direct crossings available, or alternatively you want to enhance the accuracy of the crossing, or you want to maximise the number of correspondences you can get.
We can try using multiple input dictionaries.
Let's say you want to make a Chuvash--Tatar dictionary, and you have:
- Chuvash--Russian
- Chuvash--Turkish
- Turkish--Russian
- Turkish--Tatar
- Russian--Tatar
You could make a graph out of these dictionaries where each node is a word in a language, and each arc is a language pair. For example like: http://i.imgur.com/SFOsRMv.png

You could then cluster the words using some "strongly-connected subgraph"[1] algorithm. Then assume that the sets of words within a strongly-connected subgraph are translations of each other. Meaning that you could get кил--йорт without having any direct correspondence.
vs crossdics[edit]
кил--йорт are not strongly-connected to each other, but hypothesising an arc between them would make them a strongly-connected subgraph along with ev and дом. The size of the strongly-connected subgraph (here: 4) could be an indicator of the strength of the association, but strongly-connected subgraphs might be too hard a requirement.
You could still get кил--йорт through crossdics. If crossdics gives the subgraphs of size 3 (where one arc is hypothesized), then the intersection of runs of crossdics (chv-rus-tat and chv-tur-tat) doesn't necessarily give the subgraphs of size 4 – that would require the rus-tur connection as well, while the crossdics intersection doesn't require that.
Two things we wouldn't get from crossdics:
- the fact that even with one arc missing,
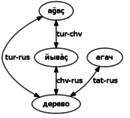 is still stronger than the simple chv-rus-tat crossdics (due to the extra route via tur),
is still stronger than the simple chv-rus-tat crossdics (due to the extra route via tur), - the possibility of adding translations where both crossings would have lacunae, but doublecrossing shows a translation:
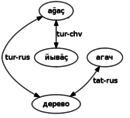
- possibly a bad translation, but if there are no shorter paths for either word, it might be worth it


{kind=link}
Restrictions on sub-graphs:[edit]
- Only one word per input language
- Prune words with only a single output arc.
- Only accept words where there is a cycle(?)
Some ideas:[edit]
- Weighting
- Outgoing arcs get 1/number of arcs?
- Using more monolingual data, e.g. each word gets an SL concordance/context vector.
Notes[edit]
Further reading[edit]
- Bilingual Dictionary Induction as an Optimisation Problem
- Compiling a Massive, Multilingual Dictionary via Probabilistic Inference
- Terminology-driven Augmentation of Bilingual Terminologies
- https://github.com/IlnarSelimcan/projectt/blob/master/bidixes2multidix.py might be helpful when getting started