Documentation of Matxin 1.0
This page is a translation from Spanish into English of most of the documentation of Matxin with some minor alterations. The original documentation can be found here. This page does not describe how to install or use Matxin, for that please see the page on Matxin.
General architecture
The objectives are open-source, interoperability between various systems and being in tune with the development of Apertium and Freeling. In order to do this, for the analysis of Spanish, FreeLing is used (as it gives a deeper analysis than the analysis of Apertium) and in the transfer and generation, the transducers from Apertium are used.
The design is based on the classic transfer architecture of machine translation, with three basic components: analysis of Spanish, transfer from Spanish to Basque and generation of Basque. It is based on previous work of the IXA group in building a prototype of Matxin and in the design of Apertium. Two modules are added on top of the basic architecture, de-formatting and re-formatting which have the aim of maintaining the format of texts for translation and allowing surf-and-translate.
According to the initial design, no semantic disambiguation is done, but within the lexica a number of named entities, collocations and other multiword terms are added which makes this less important.
As the design was object-oriented, three main objects were defined, sentence, chunk and node. A chunk can encompass a phrase, but always depending on the the output of the analyser, and a node can encompass a word, but taking into account that some words can be multiword units.
There follows a short description of each stage.
De-formatter and re-formatter
Analyser
The dependency analyser has been developed by the UPC and has been added to the existing modules of FreeLing (tokeniser, morphological analysis, disambiguation and chunking).
The analyser is called Txala, and annotates the dependency relations between nodes within a chunk and between chunks in a sentence. This information is obtained in the output format (see section 2) in an indirect way however in place of specific attributes, it is expressed implicitly in the form of the hierarchy of the tag, (for example, a node structure within another means that the node inside is dependent on the node outside).
As well as adding this functionality, the output of the analyser has been adapted to the interchange format which is described in section 2.
Information from the analysis
The result of the analysis is made up of three elements or objects (as previously described):
- Nodes: These tag words or multiwords and have the following information: lexical form, lemma, part-of-speech, and morphological inflection information.
- Chunks: These give information of (pseudo) phrase, type, syntactic information and dependency between nodes.
- Sentence: Gives the type of sentence and the dependency between the chunks of itself.
Example
For the phrase,
- "porque habré tenido que comer patatas"
The output would be made up of the following chunks:
- subordinate_conjunction: porque[cs]
- verb_chain:
- haber[vaif1s]+tener[vmpp0sm]+que[s]+comer[vmn]
- noun_chain: patatas[ncfp]
Transfer
In the transfer stage, the same objects and interchange format is maintained. The transfer stages are as follows:
- Lexical transfer
- Structural transfer in the sentence
- Structural transfer within the chunk
Lexical transfer
Firstly, the lexical transfer is done using part of a bilingual dictionary provided by Elhuyar, which is compiled into a lexical transducer in the Apertium format.
Structural transfer within the sentence
Owing to the different syntactic structure of the phrases in each language, some information is transferred between chunks, and chunks can be created or removed.
In the previous example, during this stage, the information for person and number of the object (third person plural) and the type of subordination (causal) are introduced into the verb chain from the other chunks.
Structural transfer within the chunk
This is a complex process inside verb chains and easier in noun chains. A finite-state grammar (see section 3) has been developed for verb transfer.
To start out with, the design of the grammar was compiled by the Apertium dictionaries or by means of the free software FSA package, however this turned out to be untenable and the grammar was converted into a set of regular expressions that will be read and processed by a standard program that will also deal with the transfer of noun chains.
Example
For the previously mentioned phrase:
- "porque habré tenido que comer patatas"
The output from the analysis module was:
- subordinate_conjunction: porque[cs]
- verb_chain:
- haber[vaif1s]+tener[vmpp0sm]+que[s]+comer[vmn]
- noun_chain: patatas[ncfp]
and the output from the transfer will be:
- verb_chain:
- jan(main) [partPerf] / behar(per) [partPerf] / izan(dum) [partFut] / edun(aux) [indPres][subj1s][obj3p]+lako[causal]
- noun_chain: patata[noun]+[abs][pl]
Generation
This also keeps the same objects and formats. The stages as as follows:
- Syntactic generation
- Morphological generation
Syntactic generation
The main job of syntactic generation is to re-order the words in a chunk as well as the chunks in a phrase.
The order inside the chunk is effected through a small grammar which gives the element order inside Basque phrases and is expressed by a set of regular expressions.
The order of the chunks in the phrase is decided by a rule-based recursive process.
Morphological generation
Once the word order inside each chunk is decided, we proceed to the generation from the last word in the chunk with its own morphological information or that inherited from the transfer phase. This is owing to the fact that in Basque, normally the morphological inflectional information (case, number and other attributes) is assigned to the set of the phrase, adding it as a suffix to the end of the last word in the phrase. In the verbal chains as well as the last word, it is also necessary to perform additional morphological generation in other parts of the phrase.
This generation is performed using a morphological dictionary generated by IXA from the EDBL database which is compiled into a lexical transducer using the programs from Apertium and following their specifications and formats.
Example
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT SENTENCE (CHUNK+)>
<!ATTLIST SENTENCE
ord CDATA #REQUIRED
ref CDATA #REQUIRED
>
<!ELEMENT CHUNK (NODE, CHUNK*)>
<!ATTLIST CHUNK
ord CDATA #IMPLIED
ref CDATA #IMPLIED
length CDATA #IMPLIED
type (sn|grup-sp|grup-verb|conj-subord|F|...)
si (subj|obj|...) #IMPLIED
mi CDATA #IMPLIED
prep CDATA #IMPLIED
cas CDATA #IMPLIED
casref CDATA #IMPLIED
casalloc CDATA #IMPLIED
sub CDATA #IMPLIED
subref CDATA #IMPLIED
suballoc CDATA #IMPLIED
rel CDATA #IMPLIED
relref CDATA #IMPLIED
relalloc CDATA #IMPLIED
trans CDATA #IMPLIED
subMi CDATA #IMPLIED
objMi CDATA #IMPLIED
datMi CDATA #IMPLIED
headlem CDATA #IMPLIED
headpos CDATA #IMPLIED
headsem CDATA #IMPLIED
leafpos CDATA #IMPLIED
>
<!ELEMENT NODE (NODE*)>
<!ATTLIST NODE
ord CDATA #IMPLIED
form CDATA #IMPLIED
lem CDATA #REQUIRED
pos CDATA #IMPLIED
mi CDATA #REQUIRED
ref CDATA #IMPLIED
alloc CDATA #REQUIRED
sem CDATA #IMPLIED
prep CDATA #IMPLIED
cas CDATA #IMPLIED
sub CDATA #IMPLIED
>
DTD for XML-based intercommunication format
For the previously given phrase, the stages are:
- "porque habré tenido que comer patatas"
The output from analysis is:
- subordinate_conjunction: porque[cs]
- verb_chain:
- haber[vaif1s]+tener[vmpp0sm]+que[s]+comer[vmn]
- noun_chain: patatas[ncfp]
The output from the transfer stage is:
- verb_chain:
- jan(main) [partPerf] / behar(per) [partPerf] / izan(dum) [partFut] /
- edun(aux) [indPres][subj1s][obj3p]+lako[causal]
- noun_chain: patata[noun]+[abs][pl]
After the generation phase, the final result will be:
- "patatak jan behar izango ditudalako"[1]
Although the details of the modules and the linguistic data is presented in section 3 it is necessary to underline that the design is modular, being organised in the basic modules of analysis, transfer and generation, and with clear separation of data and algorithms. And within the data, the dictionaries and the grammars are also clearly separated.
Intercommunication between modules
An XML format has been designed in order to communicate between the various stages of the translation process. All of these formats are specified within a single DTD. A format sufficiently powerful for the translation process, but also light enough to allow for a fairly fast translation process has been designed.
This format will facilitate interoperability (anyone can change any of the modules while keeping the rest the same) and the addition of new languages (although in this case the transfer phase would need to be adjusted).
Although the post-edition of the results is not one of the specified objectives of the project, the format keeps this in mind (by means of a ref tag) which will facilitate the use of these tools in future projects.
The format comes described in the following DTD which can be used in order to validate the syntax of the interchange formats.
As you can see, there are two attributes ord and alloc which are used in order to
get back the format and ref for postedition. The rest of the attributes correspond
to the previously-mentioned linguistic information.
An XSLT stylesheet has been prepared in order to see the output of each of the modules in a graphical format.
Three examples of the application of this format through each of the basic phases of translation (analysis, transfer and generation) will now be described taking as an example the translation of the phrase "Un triple atentado sacude Bagdad".
Analysis format
Is represented in an interchange format as follows:

<?xml version='1.0' encoding='iso-8859-1'?>
<?xml-stylesheet type='text/xsl' href='profit.xsl'?>
<corpus>
<SENTENCE ord='1'>
<CHUNK ord='2' type='grup-verb' si='top'>
<NODE ord='4' alloc='19' form='sacude' lem='sacudir' mi='VMIP3S0'> </NODE>
<CHUNK ord='1' type='sn' si='subj'>
<NODE ord='3' alloc='10' form='atentado' lem='atentado' mi='NCMS000'>
<NODE ord='1' alloc='0' form='Un' lem='uno' mi='DI0MS0'> </NODE>
<NODE ord='2' alloc='3' form='triple' lem='triple' mi='AQ0CS0'> </NODE>
</NODE>
</CHUNK>
<CHUNK ord='3' type='sn' si='obj'>
<NODE ord='5' alloc='26' form='Bagdad' lem='Bagdad' mi='NP00000'> </NODE>
</CHUNK>
<CHUNK ord='4' type='F-term' si='modnomatch'>
<NODE ord='6' alloc='32' form='.' lem='.' mi='Fp'> </NODE>
</CHUNK>
</CHUNK>
</SENTENCE>
</corpus>
The dependency hierarchy which has already been described here is expressed more clearly as a result of the indentation, however the programs obtain this as by the tags chunk and node. As can be seen, the format is simple but very powerful.
The same information processed by the above-mentioned stylesheet is presented to the left for the phrase "Un triple atentado sacude Bagdad".
Transfer format
The format remains the same, but the information is translated. The attribute
ref is added in order to maintain the information about the order of the source
sentence. The post-edition will require the information of interchange between
the various phases. On the other hand the information corresponding to the
attribute ord disappears as the new order will be calculated in the generation
stage.
It is also possible to see that various elements have been removed although their information has been inherited by other elements.
<?xml version='1.0' encoding='iso-8859-1'?>
<?xml-stylesheet type='text/xsl' href='profit.xsl'?>
<corpus>
<SENTENCE ord='1' ref='1'>
<CHUNK ord='2' ref='2' type='adi-kat' si='top' headpos='[ADI][SIN]' headlem='_astindu_'
trans='DU' objMi='[NUMS]' cas='[ABS]' length='2'>
<NODE form='astintzen' ord='0' ref='4' alloc='19' lem='astindu' pos='[NAG]' mi='[ADI][SIN]+[AMM][ADOIN]+[ASP][EZBU]'>
<NODE form='du' ord='1' ref='4' alloc='19' lem='edun' pos='[ADL]' mi='[ADL][A1][NR_HU][NK_HU]'/>
</NODE>
<CHUNK ord='0' ref='1' type='is' si='subj' mi='[NUMS]' headpos='[IZE][ARR]'
headlem='atentatu' cas='[ERG]' length='3'>
<NODE form='atentatu' ord='0' ref='3' alloc='10' lem='atentatu' pos='[IZE][ARR]'
mi='[NUMS]'>
<NODE form='batek' ord='2' ref='1' alloc='0' lem='bat' pos='[DET][DZH]'> </NODE>
<NODE form='hirukoitz' ord='1' ref='2' alloc='3' lem='hirukoitz' pos='[IZE][ARR]'/>
</NODE>
</CHUNK>
<CHUNK ord='1' ref='3' type='is' si='obj' mi='[NUMS]' headpos='[IZE][LIB]' headlem='Bagdad'
cas='[ABS]' length='1'>
<NODE form='Bagdad' ord='0' ref='5' alloc='26' lem='Bagdad' pos='[IZE][LIB]' mi='[NUMS]'> </NODE>
</CHUNK>
<CHUNK ord='3' ref='4' type='p-buka' si='modnomatch' headpos='Fp' headlem='.' cas='[ZERO]'
length='1'>
<NODE form='.' ord='0' ref='6' alloc='32' lem='.' pos='Fp'> </NODE>
</CHUNK>
</CHUNK>
</SENTENCE>
</corpus>
The result is the phrase: "At entatu hirukoitz batek Bagad astintzen du"[2]
Detailed architecture
It is necessary to remember that the analysis stage re-uses the FreeLing package and thus the documentation which will be used is from that project: http://garraf.epsevg.upc.es/freeling/ and also auxiliary functions from the Apertium package will be used for the generation and lexical transfer stages and in order to do de/re-formatting of texts. The documentation for this can be found on www.apertium.org and wiki.apertium.org.
The detailed architecture of Matxin can be found in figure 1.
The application which has been developed is stored in an SVN repository which is mirrored for public access at matxin.sourceforge.net. The elements in the figure can be found in four subdirectories:
trunk/src-- Here the sourcecode of the programs is found which corresponds almost one to one with the names of the processes in figure 1.trunk/data/dict-- The dictionaries used in the transfer stage and in the generation stagetrunk/data/gram-- The grammars for transfer and generationtrunk/bin-- Executable programs
As can be seen in the figure, on one hand the three phases of analysis, transfer and generation are distinguished and on the other hand the modules corresponding to the programs, the dictionaries and the grammars are distinguished. This helps to achieve an open and modular architecture which allows the addition of new languages without requiring changes in the programs. As it is free software, it will be possible to improve the system without needing to modify the programs, all that will be required is to improve and expand the dictionaries and grammars without needing to understand the code of the programs. Of course it will also be possible to modify the code.
We will now detail the elements of the various phases:
- Transfer
- LT: Lexical transfer
- Bilingual dictionary (compiled) -- (
eseu.bin) - Dictionary of chunk types -- (
eseu_chunk_type.txt) - Dictionary of semantic information -- (
eu_sem.txt)
- Bilingual dictionary (compiled) -- (
- ST_intra: Syntactic transfer within the chunk
- Grammar to exchange information between nodes (
intrachunk_move.dat)
- Grammar to exchange information between nodes (
- ST_inter: Syntactic transfer between chunks
- Verb subcategorisation dictionary (
eu_verb_subcat.txt) - Preposition dictionary (
eseu_prep.txt) - Grammar to exchange information between chunks (
interchunk_move.dat)
- Verb subcategorisation dictionary (
- ST_verb: Syntactic transfer of the verb
- Grammar of verb transfer (compiled) (
eseu_verb_transfer.dat)
- Generation
- SG_intra: Conversion and ordering within the chunk
- Dictionary of conversion of syntactic information (
eu_changes_sint.txt)
- Grammar of ordering within the chunk (
eu_intrachunk_order.dat)
- SG_inter: Ordering between chunks
- Grammar for ordering between chunks (
eu_interchunk_order.dat)
- MG: Morphological generation
- Dictionary for converting morphological information (compiled) (
eu_changes_morph.bin)
- Morphological generation dictionary (compiled) (
eu_morph_gen.bin)
- Morphological generation dictionary for any lemma (compiled) (
eu_morph_nolex.bin)
- Morphological generation dictionary for measures (
eu_measures_gen.bin)
- Morphological preprocessing grammar (
eu_morph_preproc.dat)
Now the linguistic resources which have been employed will be described and after
that the structure of the programs.
Format of linguistic data
With the objective of encouraging good software engineering as well as facilitating
the modification of the system by linguists, the linguistic information is distributed
in two types of resources (dictionaries and grammars) and these resources have been
given the most abstract and standard format possible.
As has been previously described the basic linguistic resources, with the exception
of those designed specifically for FreeLing are as follows:
- Dictionaries:
- Transfer: The Spanish→Basque bilingual dictionary, the Spanish→Basque syntactic tag dictionary, the Basque semantic dictionary, the Spanish→Basque preposition dictionary and the Basque verb subcategorisation dictionary.
- Generation: The syntactic change dictionary, the morphological change dictionary and the Basque morphological dictionary.
- Grammars:
- Transfer: grammar for the transfer of verbal chains from Spanish→Basque and Spanish→Basque structural transfer grammars
- Generation: Basque morphological preprocessing grammar, re-ordering grammar for both interchunk and intrachunk.
In the search for standardisation, the bilingual and morphological dictionaries are
specified in the XML format described by Apertium which has been made compatible
with this system.
We have tried to make the grammars finite-state, but in the case of the interchunk
movement a recursive grammar has been opted for.
A special effort has been made to optimise the verb chain transfer grammar as
the transformations are deep and may slow down the system. While standardising
this grammar, the language of the xfst package (with some restrictions) has been
chosen, it is well documented and very powerful, although it has the problem of
not being free software. As a result of this, a compiler which transforms this
grammar into a set of regular expressions that are processed in the transfer module.
The rest of the linguistic resources are grammars which take care of different
objectives and which have a specific format. At the moment they have a format
which is not based on XML but one which has been aimed at finding a compromise
between something which is comprehensible for linguists and which is easily
processed by the programs. In the future formats and compilers will be designed which
will make the grammars more independent of the programs.
In any case the linguistic data is separated from the programs so that it can
allow third parties to modify the behaviour of the translator without needing
to change the source code.
Spanish→Basque bilingual dictionary
This follows the Apertium specification. It has been obtained from part of the Elhuyar
bilingual dictionary and it contains the Basque equivalents for each of the entries
in Spanish present in the FreeLing dictionary. Although a fraction of these equivalents
are distributed on the SourceForge mirror site. The dictionary creation process
is described in depth in reference.[6]
Given that there is no semantic disambiguation, only the first entry for each word
has been entered (except with the prepositions which have been kept), but in order
to improve the situation many multiword units have been entered, from both the
Elhuyar dictionary and through an automatic process of searching for collocations.
In annex 2 the format (which is described in chapter 2 of reference [1]) will be
presented and a small part of the bilingual dictionary.
Syntax tag dictionary
In this dictionary the equivalences between the syntactic tags that are given
by the FreeLing analyser and the tags which are used in the transfer and
generation of Basque are found. It is a very simple dictionary that allows
us to remove the code for these transformations.
- Format
es_chunk_type eu_chunk_type #comment
Example of the content of this dictionary
sn is #sintagma nominal izen-sintagma
s-adj adjs #sintagma adjetivo adjektibo-sintagma
sp-de post-izls #sint. preposicional con la prep. "de" izenlagun-sintagma
grup-sp post-sint #sint. preposicional (excepto "de") postposizio-sintagma
Fc p-koma #signo de puntuación "coma" puntuazioa: koma
F-no-c p-ez-koma #signos de puntuación(excep. "coma") koma es diren punt-ikurrak
número zki #cualquier número cardinal edozein zenbaki kardinal
grup-verb adi-kat #grupo verbal aditz-katea
sadv adbs #sintagma adverbial adberbio-sintagma
neg ez #negación ezeztapena
coord emen #conjunción coordinada emendiozko juntagailua
Preposition dictionary
In this dictionary the prepositions of Spanish are found along with their possible
translations in Basque (a case and sometimes a preposition), the selection condition
(if there is one) of any of the possible translations, and if after seeing these
conditions there is still more than one possible translation, a mark which shows
which of the equivalences have been taken into account in the process of selection
with information from verb subcategorisation.
- Format
es_preposition eu_case selectionCondition subcategorisation
The selection condition has the format chunk-attribute='value'
where chunk can be "my" or "parent" depending on if it refers to an attribute of its
own chunk or to an attribute in an ancestor chunk.
The field case_eu can be of two types:
- A single declination class
- A declination class ++ a preposition / declination class of the preposition
The declination class of the preposition will be used in the process of selection
with verb subcategorisation.
- Example
en [INE] - +
a +[AMM][ADIZE]+[DEK][ALA] my.headpos='[ADI][SIN]' -
a [INE] my.headpos='[Zm]' -
a [DAT] - +
a [ABS] - +
a [ALA] my.si='cc' +
ante [GEN]++aldean/INE parent.headlem='izan' -
ante [GEN]++aurrean/INE - +
ante [GEN]++aurrera/ALA - +
Verb subcategorisation dictionary
This dictionary is used in the process of selecting the correct translation of
the prepositions of the complements which accompany a verb.
It includes the information about transitivity of each verb.
- Format
VerbEu transitivity/subjectCase1/complementCase2#transitivity2/subjectCase2...
The different possibilities of subcategorisation appear in frequency order
from most frequent to least frequent according to corpus counts.
For some verbs it only gives information on transitivity
- Example
aberastu DU/ERG/ABS#DA/ABS/#DU/ERG/#DA/ABS/EN_BIDE#DU/ERG/ABS-INS#DU/ERG/ADJ#DA/ABS/ADJ#
abestu DU/ERG/ABS#DU/ERG/#DU/ERG/ABS-INE#ZAIO/ABS/DAT#DU/ERG/INE#DA/ABS/#
DU/ERG/ADJ#DU/ERG/EN_ARABERA#DU/ERG/AZ-INE#DU/ERG/ABS-INS#DU/ERG/INS#DA/ABS/INE#
ZAIO/ABS/DAT-INS#ZAIO/ABS/DAT-INE#DA/ABS/INS#
abisatu DIO/ERG/DAT#DU/ERG/#DIO/ERG/ABS-DAT#DU/ERG/KONP#DIO/ERG/DAT-INE#
DU/ERG/INE#
absolbitu DU/ERG/#DU/ERG/ABS#DU/ERG/ABL#DU/ERG/ABS-ALA#DU/ERG/ABS-ADJ#
DU/ERG/ABS-MOT#DU/ERG/INS#
jario ZAIO//#
jaulki DU/ZAIO//#
jaundu ZAIO//#
zuzenarazi DA-DU//#
zuzeneratu DA-DU//#
zuzperrarazi DU//#
Semantic dictionary
In order to take some decisions in the translation process there are points where
it is necessary to have semantic information about the words. This dictionary contains
information about the semantic feature of the words.
- Format
nounEu [semanticFeature Sign]
semanticFeature is the identification of a semantic feature and Sign
is one of the signs +, -, or ?. The symbol '?' is used when for some of the
translations it might be positive and for others negative o when it hasn't been
possible to establish the direction.
At the moment only the information about the semantic feature "animate / inanimate"
although in the future other necessary features will be included.
- Example
abarka [BIZ-]
abarkagile [BIZ+]
abarketa [BIZ-]
abarketari [BIZ+]
abaro [BIZ-]
abarrategi [BIZ-]
abat [BIZ?]
abata [BIZ-]
abatari [BIZ+]
Syntactic change dictionary
To order the nodes within a chunk specific syntactic information is needed about
the category of the nodes. In the case that the determiners will vary according
to the lemma of the determiner (meaning that a determiner of one type may appear
before a noun or another of the same type after).
At the moment in this dictionary, the second column indicates which determiners
are put before ([DET][IZL]) and which after ([DET][IZO])
according to the lemma and the category, information which is expressed in the first
column.
- Format
lema[syntacticInformation] lema[orderingInformation]
- Example
asko[DET][DZG] asko[DET][IZO]
bana[DET][BAN] bana[DET][IZO]
bat[DET][DZH] bat[DET][IZO]
beste[DET][DZG] beste[DET][IZL]
Morphological changes dictionary
In order to generate the superficial form of the words in Basque it is necessary
to inflect, which involves knowing the lemma, the word category and the information
about case and number. However, sometimes the category which comes from the bilingual
dictionary and which is used for ordering words within the chunk does not coincide
with the set of categories used in the morphological dictionary. In this case we
need to know the information on category which serves for the generation. This information
can be obtained using the dictionary of morphological changes which follows the
Apertium XML format.
- Example
<?xml version="1.0" encoding="iso-8859-1"?>
<dictionary>
<alphabet/>
<sdefs/>
<pardefs/>
<section id="main" type="standard">
<e><p><l>aarondar[IZE][ARR]</l><r>aarondar[ADJ][IZO]</r></p></e>
<e><p><l>janari-denda[IZE][ARR]</l><r>denda[IZE][ARR]</r></p></e>
<e><p><l>janari-saltzaile[IZE][ARR]</l><r>saltzaile[IZE][ARR]</r></p></e>
<e><p><l>abade[ADJ][IZL]</l><r>abade[IZE][ARR]</r></p></e>
<e><p><l>abadearen[ADJ][IZL]</l><r>abade[IZE][ARR]+[DEK][GEN]</r></p></e>
<e><p><l>beira-ale[IZE][ARR]</l><r>ale[IZE][ARR]</r></p></e>
<e><p><l>aitzindari izan[ADI][SIN]</l><r>izan[ADI][SIN]+[AMM][ADOIN]
</r></p></e>
<e><p><l>bandotan antolatu[ADI][SIN]</l><r>antolatu[ADI][SIN]+[AMM][PART]
</r></p></e>
<e><p><l>haize eman[ADI][SIN]</l><r>eman[ADI][SIN]+[AMM][ADOIN]</r></p></e>
<e><p><l>haize emate[IZE][ARR]</l><r>eman[ADI][SIN]te[ATZ][IZE][ARR]
</r></p></e>
...
Morphological dictionary
Basque morphology is complex and owing to its agglutinative character, much
of the standard free software for dealing with morphology (such as ispell
or aspell) is not well adapted for it. When the IXA group designed the morphological
processor for Basque, it opted for two-level morphology, based on lexica and
morphological rules which allow the compilation of a transducer for both
analysis and generation.
The problem is that at the time, there was no free software capable of compiling
or transforming two level morphologies (currently there are two packages capable
of doing this: sfst from Stuttgart and hfst from Helsinki). As a result of this
restriction, it was opted to transform the dictionaries and rules into the Apertium
format, removing the phonological changes and transforming them into additional
paradigms. With this, pseudo-lemmas and pseudo-morphemes are generated which do
not correspond to canonical forms.
This is inconvenient as the Apertium format is less expressive than two-level
rules and the transformation was complicated and in some cases it was necessary
to put up with lower coverage or overgeneration. The main problem is that it has
limited the capacity of agglutinating morphemes in Basque, and as a result that
although for generation this will not be a problem, it will be problematic if
anyone wants to use the dictionary for analysis.
Furthermore, as it was generated automatically and uses non-canonical forms, the
readability and comprehensibility suffers.
The Apertium format is the same as the bilingual dictionary which is described
exhaustively in chapter 2 of reference [1]. It is composed of a section for the
alphabet, another for the tags, a third for the paradigms and a fourth for
the mappings between lemma and paradigms. In annex 3 a small part of the
morphological dictionary is presented. The source file is XML and the output is a
binary transducer.
Verb chain transfer grammar
This is one of the most complicated parts of the sytem as verbs chains are
very different in the two languages. In reference [3] a description is
made of the format and the function of the rules which are applied.
For the moment the format follows the syntax of xfst, that although it is not
a standard and nor is it free software, it is well known for its power, flexibility
and documentation. As a first attempt, it was attempted to convert the grammar
to that of the free FSA, however there were problems in the tests due to the
restrictiveness of the format and finally the problems of efficiency made
it unworkable. In the end, a translator (fst2regex.pl) was created for the grammar
(based on the syntax of xfst) eseu_verb_transfer.fst to a set of regular
expressions eseu_verb_transfer.dat which are read and processed by one of the
modules in the system.
The regular expressions are applied one by one to an input which contains the
information of the analysis of the verb chain in Spanish, as well as the information
of agreement with the objects and any information about subordination. The
regular expressions make modifications to this input until they create an output
which contains all of the information necessary to generate the verb chain in
Basque.
Grammar
The grammar is composed of three groups of rules:
- Rules for identification and tagging
- Rules for the conversion of attributes
- Rules for the removal of superfluous information
The first are very simple and tag the different types of verb chains identified,
six in total. The generic format is as follows:
[ esVerbChainType @-> ... BORDER euVerbChainSchema ]
The part on the left is a regular expression which identifies the type of verb chain
which is looked for in Spanish and the part on the right gives a set of attributes
corresponding to a schema of the equivalent verb chain in Basque.
The rules for the conversion of attributes which form the second group have the
following structure:
[ "euAttribute" @-> "euValue" || ?* esValues ?* BORDER ?* euValues ?* _ ]
which indicates the value which an attribute takes in a given specified context.
The philosophy is that the first rules add various abstract attributes, and
that these attributes are then substituted for concrete values according to
the elements of the verb chain in Spanish, adding this information on the right side.
Finally, the removal rules get rid of information of the attributes in Spanish
which aren't needed in the rest of the translation process.
- Example
- "porque no habré tenido que comer patatas"
The information given by the analyser is as follows:
- conjunction: porque[cs]
- negative: no[rn]
- verb_chain: haber[vaif1s]+tener[vmpp0sm]+que[cs]+comer[vmn]
- noun_chain: patatas[ncfp]
Which after the process of lexical transfer is given as:
- haber[vaif1s]+tener[vmpp]+que[cs]+comer[vmn]/[tr][3p][caus]/jan
A rule of the first time (identification and tagging) with the form:
[ esVerbChainTypePerif1 @->... BORDER euVerbChainSchemaP1 ]
Transforms it into:
haber[vaif1s]+tener[vmpp]+que[cs]+comer[vmn]/[tr][3p][caus]/jan
==>P1> (main)Aspm/Per Aspp/Dum Aspd/Aux TenseM SubjObjDat +RelM
One of the rules that transforms the periphrastic verbs looks like:
[ [ "Aspp" @-> "[partFut]" || ?* [VMIF|VMIC|VAIC] ?* BORDER "P1" ?* _ ]
.o. [ "Aspp" @-> "[partImp]" || ?* [VMIP|VMII] ?*
BORDER "P1" ?* [{hasi}|{amaitu}|{utzi}|{joan} ] _ ]
.o. [ "Aspp" @-> "[verbRad]" || ?* BORDER "P1" ?* {ari} ?* _ ]
.o. [ "Aspp" @-> "[partPerf]" || ?* BORDER "P1" ?* ]
This transforms the input into:
haber[vaif1s]+tener[vmpp]+que[cs]+comer[vmn]/[tr][3p][caus]/jan
BORDER P1> (main)[partPerf] / behar(per)[partPerf] / izan(dum)[partFut]
/ edun(aux)[indPres][subj1s][obj3p]+lako[causal morpheme]
Which after the cleaning ends up as:
jan(main)[partPerf] / behar(per)[partPerf] / izan(dum)[partFut]
/ edun(aux)[indPres][subj1s][obj3p]+lako[causal morpheme]
Compiled regular expressions
The format of the regular expressions after compilation is as follows:
leftContext chainToSubstitute rightContext substitutingString
- Example
*?\.querer\..*? Per .*? nahi_izan
.*?(\=\=\>)P1.*? ari_izan <PER>ADOIN.*? aritu
.*?\.acabar\..*?\.de\..*?\/ Prt .*? berri<PRT>[ADJ][IZO]
.*?dat2s.*? Ni .*? [NI_ZU]
In the first rule, for example, if it finds the chain "Per", having the
left context ".querer.", it substitutes "Per" for "nahi_izan".
Intrachunk movement grammar
In this phase it is necessary to pass information from some of the nodes to
the chunks to which they belong. These movements are defined in this grammar.
- Format
nodeCondition/originAttribute chunkCondition/destinationAttribute writeMode
Where writeMode can be overwrite, no-overwrite or concat.
- Example
mi!='' /mi type!='adi-kat' /mi no-overwrite
mi='[MG]' /mi type!='adi-kat' /mi overwrite
prep!='' /prep /prep concat
prep!='' /ref /casref concat
prep!='' /alloc /casalloc concat
pos!='' /pos /headpos no-overwrite
lem!='' /lem /headlem no-overwrite
sem!='' /sem /headsem no-overwrite
pos='[Z]' /pos /leafpos overwrite
pos='[Z]' /'[MG]' /mi overwrite
pos='[Zu]' /'[MG]' /mi overwrite
If the condition is fulfilled both in the node and in the chunk (in the condition,
one or more attributes and the value that they should or shouldn't have is
specified), the value which is found in the origin attribute is passed to the
destination attribute in the chunk in one of three writing modes:
overwrite (where it is written, deleting what was previously in the attribute),no-overwrite (where it is only written if the attribute has no previous value) andconcat (where the value is added to the previous content of the attribute).
For example, if we interpret the first two rules of the example, in a verbal
chunk (adi-kat), the morphological information (mi</cide>) of the first of the nodes
which have any information information to the chunk. The information of those
following will not be passed providing it doesn't have the value '[MG]'.
Interchunk movement grammar
In this phase it is necessary to pass information between chunks. This is defined
in this grammar.
- Format
nodeCondition/originAttribute chunkCondition/destinationAttribute direction writeMode
Where direction can be either up or down.
- Example
sub!=''&&type='adi-kat' /sub si='obj' /cas down overwrite
sub!='' /sub type='adi-kat' /rel down no_overwrite
sub!='' /subref type='adi-kat' /relref down concat
sub!='' /suballoc type='adi-kat' /relalloc down concat
type='ez' /'adi-kat-ez' type='adi-kat' /type up overwrite
si='subj' /mi type='adi-kat' /subMi up overwrite
si='obj' /mi type='adi-kat' /objMi up overwrite
si='iobj'&&cas!='[DAT]' /mi type='adi-kat' /objMi up overwrite
Between two chunks information of the source attribute to the target attribute
will be passed, if it fufills the condition for both chunks. The condition
gives one or more attributes and the value which they should or shouldn't
contain. This process is applied in one of the three write-modes (see previous
section), and in the direction marked, either down (the source chunk is the parent
and the target chunk is its child) or up (the source chunk is the child of the
parent chunk to which it passes the information).
In the last rule in the example, it says that if a chunk has syntactic
information (si) with the value iobj (indirect object) and its case is
not '[DAT]' (dative), it will pass the information in the attribute 'mi' to
the chunk which is above it (direction 'up') overwriting the contents of the
attribute 'objMi', proving that the chunk is of type 'adi-kat'.
Basque morphological preprocessing grammar
To generate the superficial form of the words in Basque that need to be generated
it is necessary to have the lemma, the part-of-speech, the case and the number.
However, depending on the part-of-speech and case this information needs to be
ordered in one way or another in order to generate correctly (as the morphemes
aren't always added in the same order). This grammar defines the ordering of this
information
- Example
[IZE][(IZB)](.*?)[(INE|ALA|ABL|ABU|GEL)] LemaMorf +[DEK] Num +[DEK] Kas
[IZE][(IZB|LIB)] LemaMorf +[DEK] Kas [MG]
...
[DET][ERKARR][NUMS](.*?)[(ABS|SOZ|DES|GEN)] LemaMorf +[DEK] Kas
[DET][ERKARR][NUMS](.*?)[(ERG|DAT)] LemaMorf +[DEK] Kas Num
[DET][ERKARR][NUMS](.*?)[(INE|ABL)] LemaMorf +[DEK] [MG] +[DEK] Kas
[DET][ERKARR][NUMS](.*?)[(.*?)] LemaMorf +[DEK] Num +[DEK] Kas
...
[DET][ERKARR](.*?)[(SOZ|DES|GEN)] LemaMorf +[DEK] Kas
[DET][ERKARR](.*?)[(ABS|ERG|DAT|INS)] LemaMorf +[DEK] Kas Num
[DET][ERKARR](.*?)[(.*?)] LemaMorf +[DEK] Num +[DEK] Kas
...
gutxi[DET][DZH](.*?) LemaMorf +[DEK] Kas
...
(.*?) LemaMorf +[DEK] Num +[DEK] Kas
In the left-hand column a regular expression is given where any information can
appear, for example, the lemma, the morphological or syntactic information and
the case of the word to be generated. According to this information the morphemes
are re-ordered in the order indicated by the second column. "lemaMorf" gives
the lemma and the syntactic information, "Num" gives the number and "Kas" the
case.
Thusly we can see that in order to generate the declined forms of the demonstrative
determiners in the singular "[DET]ERKARR][NUMS]" "hau", "hori" and "hora", depending
on the case they are ordered differently than those in the plural "hauek", "horiek"
and "haiek".
Sometimes, for example for "gutxi", this word is ordered differently than the
rest of the words in this category.
On the last line the default order of morphemes is defined.
Basque intrachunk ordering grammars
The nodes within a chunk in Basque are ordered according to the patterns defined
in this grammar.
- Format
chunkType (syntacticInformation)...(syntacticInformation)([BURUA])(syntacticInformation)...(syntacticInformation)
[BURUA] is the place where the root node of the chunk is placed. The rest of the
nodes are placed according to their syntactic information
- Example
is
([DET][IZL])([DET][IZL])([DET][IZL])([DET][IZL])([DET][ORD])([Z])([ADB][ADOARR])([ADJ]
[IZL])([ADJ][IZL])([ADJ][IZL])([ADJ][IZL])([IZE][IZB])([IZE][IZB])([IZE][IZB])([IZE][I
ZB])([IZE][ARR])([IZE][ARR])([BURUA])([ADJ][IZO])([ADJ][IZO])([ADJ][IZO])([LOT][JNT])(
[ADJ][IZO])([DET][IZO])([DET][IZO])([DET][IZO])([DET][IZO])
adi-kat ([ADB])([BURUA])([PER])([PRT])([ADM])([ADL])
adi-kat-ez ([PRT])([ADL])([ADB])([BURUA])([PER])([ADM])
For example, for verb chains in affirmative sentences (adi-kat), they are
ordered by putting before the root note, the note which has an adverb ([ADB]) if
it exists and after a periphrastic verb ([PER]) the verbal particle ([PRT])
the modal verb ([ADM]) or the auxiliary verb ([ADL]), in this order and providing
they exist.
For example, for verb chains in affirmative sentences (adi-kat), are ordered
by putting the adverb ([ADB]), if it exists, before the root node. After the
periphrastic verb ([PER]) comes the verbal particle ([PRT]), the modal
verb ([ADM]), and the auxiliary verb ([ADL]). This order is followed providing
that all of them exist.
It can be seen that in verb chains in negative sentences however (adi-kat-ez) the
order changes, putting the verbal particle ([PRT]) before the auxiliary verb ([ADL]),
and the adverb before the periphrastic verb ([PER]) and the modal.
The translations of "he tenido que venir" and "no he tenido que venir" would be
ordered in the following way:
adi-kat >> etorri behar izan dut
[BURUA] [PER] [ADM] [ADL]
adi-kat-ez >> dut etorri behar izan
[ADL] [BURUA] [PER] [ADM]
Basque interchunk ordering grammars
The order of the chunks in a phrase is decided following a recursive process,
which traverses the tree in post-order, ordering each chunk with each of the
chunks that are attached.
- Format
parentChunkType childChunkType relativePosition order
Where order can be specified as follows:
- x1.x2 -- The child chunk (x2) is put after the last chunk ordered up until now
- --x1-- => --x1--x2
- x2.x1 -- The child chunk (x2) is put immediately before the parent chunk
- --x1-- => --x2 x1--
- x2+x1 -- The child chunk (x2) is put immediately before the parent chunk (x1)
- making sure that no other chunk is put between them. If another chunk
- needs to be put after (with the order x2.x1 or x2+x1) it is put
- immediately after the chunk we've just ordered.
- --x1-- => --[x2 x1]--
relativePosition gives the position where the child chunk will be found with
respect to the parent chunk in the source language sentence.
- Example
adi-kat-ez ez .*? x2+x1
adi-kat .*? >1 x1.x2
adi-kat .*? =1 x2.x1
adi-kat .*? <1 x2.x1
.*? .*? .*? x2.x1
When a verbal chain chunk (adi-kat-ez) has a leaf chunk of type 'ez' (a negative
verbal particle equivalent to 'no' in Spanish) this particle is put immediately
in front of the verbal chain and no other chunk can be put between them.
On the other hand, chunks that depend on an adi-kat chunk are put in front if
in Spanish they are found in front of a verb (relative position < 1), or immediately
after it (rel. pos. = 1). Ths chunks which are found in Spanish more to the right
in Basque are also put after, leaving one after another in the same order that
they were in Spanish.
For example the phrase "Yo corto el pan en casa para ti"
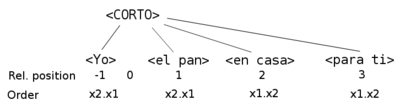

is ordered as follows:
<Nik><ogia><MOZTEN DUT><etxean><zuretzat>
(yo) (el pan) (corto) (en casa) (para tí)
Program design
In chapter two the general scheme has been described and in chapter four, the
modules which make up the program. In this chapter we would like to expand
on this in more detail, and more from the angle of software development.
The analyser, the transfer module and the generation module are the three
fundamental components of the system (see figure 1). These modules communicate
between themselves using an XML structure defined in chapter three.
The first element, the analyser has been developed by the UPC and is
distributed and documented independently in the package
FreeLing (http://garraf.epsevg.upc.es/freeling/).
The transfer and generation modules have a coherent design and implementation
which makes use of, when appropriate, the basic modules from the package
Apertium (http://www.apertium.org)
The programs which are referred to in the following sections are available under
the GPL in the Matxin package (http://matxin.sourceforge.net).
Methodology and object orientation
As previously mentioned, an object oriented design has been implemented where
the basic objects are the interchange format elements: node (word/lemma),
chunk (pseudo-phrase) and sentence. As can be seen in the examples in
chapter 4, with these elements a dependency tree of chunks of the phrase
is represented, along with the dependencies between words/lemmas in each chunk,
and the information of each word/lemma.
For the example which has been previously used:
- "porque habré tenido que comer patatas"
The information that comes out of the analyser will be as follows:
- A sentence
- Three chunks: porque, habré_tenido_que_comer and patatas, in this dependency order, with the second depending on the first and the third on the second.
- The second chunk is divided into four nodes, where comer is the root node and the other three depend on it.
This is represented as a tree (which will be the internal representation which
is used) in the following way:
<SENTENCE ord="1">
<CHUNK ord="1" type="conj-subord">
<NODE ord="1" form="porque" lem="porque" mi="CS" alloc="1"/>
<CHUNK ord="2" type="grup-verb">
<NODE ord="4" form="comer" lem="comer" mi="VMN0000" alloc="25">
<NODE ord="1" form="habré" lem="haber" mi="VAIF1S0" alloc="8"/>
<NODE ord="2" form="tenido" lem="tener" mi="VMP00SM" alloc="14"/>
<NODE ord="3" form="que" lem="que" mi="CS" alloc="21"/>
</NODE>
<CHUNK ord="3" type="sn" si="obj">
<NODE ord="1" form="patatas" lem="patata" mi="NCFP000" alloc="31"/>
</CHUNK>
</CHUNK>
</CHUNK>
</SENTENCE>
In both the transfer as in the generation various stages are required. In transfer
the lexical and syntactic transfer are distinguished, and in generation, syntactic
and morphological. Structural transfer is divided in turn into subphases. We will
call intra the process which deals with nodes within a chunk, and inter the process
which treats chunks within a phrase.
Where possible the linguistic data has been separated from the algorithmic
code, coming out with the grammars, dictionaries and other elements described
in chapter 4.
In the next pages we describe the modules in more detail.
Transfer modules
The transfer process is complicated and has two basic modules:
- Lexical transfer
- Structural transfer
The structural transfer has two modules intra and inter which are described
later.
Lexical transfer
This is based on the bilingual dictionary described in section 4.1. All of the
lemmas coming from Spanish apart from the verb nodes which aren't
roots (auxiliary verbs and components of periphrastic verbs). These are marked
and left for transformation in the structural transfer.
The pseudo-algorithm is as follows:
conversion of attribute ord to ref (sentence, chunk, node)
for chunk in chunks:
if chunk == verbal chunk:
for node in nodes:
if node == chunk root:
dictionary_lookup_lemma_pos (node)
else:
no_transfer_mark_lemma (node)
else:
dictionary_lookup_lemma_pos_im (node)
semantic_lookup (node)
Structural transfer
This is implemented by doing transfers of attributes between nodes and chunks and
in between chunks in order to get an equivalent structure in the target language.
- Intrachunk structural transfer
The object to be processed is the chunk. In general attributes of the node
are passed to the chunk to which they belong following the grammar of
information exchange. When a node is left without a lemma, it is removed.
The pseudo-algorithm:
for chunk in chunks:
for node in nodes:
raise_attributes (grammar, nodes, chunk)
if lemma == null:
remove_node (node)
- Interchunk structural transfer
The object to be processed is the sentence. Attributes of a chunk are passed
to another chunk according to the grammar. This also tries to identify the
case of noun phrases (chunks) according to the type of main verb and the
prepositions from the rest of the chunks, it also decides the transitivity of
the verb in Basque.
The pseudo-algorithm:
for chunk in chunks:
lower_attributes (current_chunk, chunk_dependents, grammar)
translate_prepositions (chunk_dependents)
if chunk == verbal chunk:
subcategorisation (current_chunk, chunk_dependents)
assign_transitivity (current_chunk)
raise_attributes(current_chunk, chunk_ascendents)
if chunk == null:
remove_chunk (chunk)
- Verb structure transfer
Uses the verb chain transfer grammar described in section 4.3 directly.
Pseudo-algorithm:
for chunk in verbal_chunks:
apply_grammar_transfer (chunk)
Generation modules
As in the transfer there are two main stages however the order is reversed;
first the syntactic generation is performed (which as the syntactic transfer
works on the chunk and sentence level) and then the morphological generation
is performed (which works on the node level).
Syntactic generation
The first part is the re-ordering of chunks within the sentence (inter) and then
the re-ordering of nodes within the chunks (intra).
- Interchunk syntactic generation
Works recursively and follows the interchunk ordering grammar. It traverses the
tree in post-order and decides the relative order of a chunk and its children
according to the rules defined in the grammar.
The pseudo-algorithm:
for chunk in order(chunk, post-order)
define_order (chunk->parent, chunk->child)
- Intrachunk syntactic generation
Orders the nodes within the chunks according to a regular expression grammar. This
element is describes in part 5.13, the grammar is in trunk/data/gram/eu_intrachunk_order.dat
Pseudo-algorithm:
for chunk in chunks:
define_order (chunk->nodes)
Morphological generation
Finally, the morphological information from the chunk is transferred to the node
corresponding to the last word in order to make use of this information in the
next stage.
This stage is based on the morphological dictionary described in section 4.2.
Additionally there are two hash tables aiming at filling out and ordering
the information.
Pseudo-algorithm:
for chunk in chunks:
node = bilatu_azken_hitza
egokitu_lema_pos (node)
kontsultatu_sorkuntzako_hash (node)
kontsultatu_ordenaketa_hash (node)
sortu_forma (node)
Notes