Difference between revisions of "User:Sphinx/Application for "Adopt a language pair" GSOC 2013"
Jump to navigation
Jump to search
| Line 8: | Line 8: | ||
'''Github repo: ''' https://github.com/sphinx-jiang |
'''Github repo: ''' https://github.com/sphinx-jiang |
||
| + | == Tasks and proposed ideas == |
||
| + | === Interface for creating tagged corpora === |
||
| + | Related tasks: |
||
| + | Interface for creating tagged corpora |
||
| + | * Making an interface where you can load a raw text of, say, 30.000 words or (optional) create a corpus or X size for a given language from Wikipedia |
||
| + | * The interface should be able to take a non-disambiguated tagged corpus and be able to disambiguate it manually |
||
| + | * And, a user-friendly interface to train a supervised tagger |
||
| + | ==== Proposed idea ==== |
||
| + | To create a tagged corpus there are 2 interfaces, the first one to introduce a corpus (and modify it if you want), and the second one to actually tag the corpus (for this task I have design 2 versions) |
||
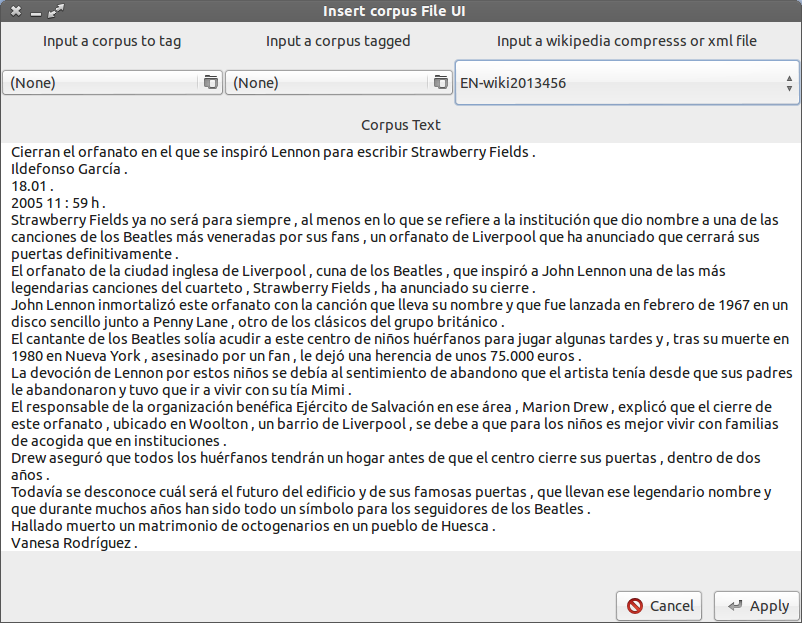
| + | The first interface is really simple, it is the '''Input corpus file UI''': |
||
| − | {| class="wikitable" border="1" |
||
| + | [[Image:Apertium input file UI.png|center|Input corpus file UI]] |
||
| − | |- |
||
| − | ! timetable |
||
| − | ! day1 |
||
| − | ! day2 |
||
| − | |- |
||
| − | | row 1, cell 1 |
||
| − | | row 1, cell 2 |
||
| − | | row 1, cell 3 |
||
| − | |- |
||
| − | | row 2, cell 1 |
||
| − | | row 2, cell 2 |
||
| − | | row 2, cell 3 |
||
| − | |} |
||
| + | ==== How it works: ==== |
||
| − | <ref>foot note</ref> |
||
| + | * You are able to select a corpus file and introduce the content into the text view |
||
| + | * Introduce a corpus already tagged |
||
| + | * Introduce a compress dump wikipedia file |
||
| + | * Modify (or directly enter a new corpus from scratch) the actual corpus |
||
| + | * Once you finish your edition you click on the apply button and appears the corpus tagger UI |
||
| + | |||
| + | |||
| + | After insert a file and click apply it tag with the corpus (if it isn't yet) and shows the '''supervised corpus tagger UI''': |
||
Revision as of 08:31, 19 April 2013
Contents
Contact information
Name: Yishan Jiang
Email: yishanj13@gmail.com
IRC: sphinx
Github repo: https://github.com/sphinx-jiang
Tasks and proposed ideas
Interface for creating tagged corpora
Related tasks: Interface for creating tagged corpora
- Making an interface where you can load a raw text of, say, 30.000 words or (optional) create a corpus or X size for a given language from Wikipedia
- The interface should be able to take a non-disambiguated tagged corpus and be able to disambiguate it manually
- And, a user-friendly interface to train a supervised tagger
Proposed idea
To create a tagged corpus there are 2 interfaces, the first one to introduce a corpus (and modify it if you want), and the second one to actually tag the corpus (for this task I have design 2 versions)
The first interface is really simple, it is the Input corpus file UI:

How it works:
- You are able to select a corpus file and introduce the content into the text view
- Introduce a corpus already tagged
- Introduce a compress dump wikipedia file
- Modify (or directly enter a new corpus from scratch) the actual corpus
- Once you finish your edition you click on the apply button and appears the corpus tagger UI
After insert a file and click apply it tag with the corpus (if it isn't yet) and shows the supervised corpus tagger UI: